📌 Úvod: O čem případová studie je
GPT Shopping klade na produktová data úplně jiné nároky než klasické produktové kampaně. Nestačí mít vyplněný popis produktu. Rozhodující je kontext, relevance a kvalita dat, ze kterých jazykový model čerpá.
V této případové studii ukazujeme konkrétní postup optimalizace produktových popisků a dalších dat pro GPT Shopping. Popisujeme, jak nad obsahem přemýšlíme v praxi, jaké zdroje informací využíváme a jak je připravujeme tak, aby s nimi šlo efektivně pracovat.
Pracujeme s reálným e‑shopem běžícím na Shoptetu (e‑shop Dykka) a s nástrojem Mergado, který slouží jako centrální místo pro přípravu a správu dat. Neřešíme jen samotné produktové popisy, ale i další obsah, který má e‑shop k dispozici, tedy články, popisy kategorií, recenze nebo informace o značkách.
Základní princip je jednoduchý:
👉 kvalitní výstup pro GPT Shopping nevzniká z jednoho textu, ale z dobře připraveného kontextu.
V dalších kapitolách proto projdeme jednotlivé typy obsahu, jejich přípravu pro produktový feed a způsob, jak je následně využít při generování popisků pomocí jazykového modelu.
🗂️ Příprava dat pro kontext
Pro GPT Shopping nestačí samotný popis produktu. Jazykový model pracuje s kontextem, který vzniká z různých zdrojů obsahu napříč e‑shopem.
Proto jsme do optimalizace zapojili více typů informací – od článků přes popisy kategorií až po recenze nebo informace o značkách. V následujících kapitolách je projdeme postupně a ukážeme, proč dávají smysl.
📝 Články (interní i externí)
Články patřily mezi nejdůležitější zdroje kontextu. Obsahují informace, které se do produktových popisků běžně nedostanou, ale pro GPT Shopping mají vysokou hodnotu.
Typicky jde o:
- způsob použití produktu v praxi,
- konkrétní scénáře a situace,
- hlavní benefity a rozdíly,
- informace o tom, pro koho je produkt určený (persony).
Ne každý článek je ale relevantní pro celý sortiment. Prvním krokem proto bylo filtrování a segmentace obsahu, nejčastěji podle kategorií nebo témat. Smyslem nebylo články kopírovat do feedu, ale vybrat jen to, co dává smysl pro daný typ produktů.
Vedle vlastního obsahu e‑shopu jsme zohlednili i externí články. Ty se hodí hlavně u produktů, které prodává více e‑shopů, a mohou přinést:
- jiný úhel pohledu,
- srozumitelnější vysvětlení použití,
- nebo doplňující informace, které na e‑shopu chybí.
Jak jsme články připravili
Aby šel obsah článků efektivně použít při generování popisků, bylo potřeba jej nejdřív připravit do vhodné podoby.
Postupovali jsme takto:
- z webu e‑shopu nebo ze sitemapy jsme posbírali relevantní URL adresy článků,
Jak jsme obsah využili v Mergadu
Hotová shrnutí jsme:
- nahráli do rozšíření Mergado Files,
- zpřístupnili přes URL adresy,
- a využívali je přímo v promptu při generování popisků.
Tento obsah se neexportoval do finálního feedu. Sloužil čistě jako doplňkový kontext pro jazykový model, který měl díky tomu k dispozici správné informace ve správný moment.
📋 Popisy kategorií
Popisy kategorií jsme použili jako širší kontext nad rámec jednotlivých produktů. Zatímco produktový popis řeší konkrétní vlastnosti a benefity, popis kategorie pomáhá jazykovému modelu pochopit:
- jaký typ produktů do kategorie patří,
- jaké jsou mezi nimi rozdíly nebo alternativy,
- jaký problém nebo potřebu daná kategorie obecně řeší.
Tyto informace se hodí zejména v situacích, kdy samotný produktový popis nestačí nebo je příliš stručný.
Jak jsme popisy kategorií připravili
Vzhledem k tomu, že e‑shop běží na Shoptetu, využili jsme jako primární zdroj dat feed kategorií ze Shoptetu.
Postup byl následující:
- feed kategorií jsme nahráli do pomocného projektu v Mergadu,
- v projektu jsme upravili výstup tak, abychom získali:
- název kategorie,
- odpovídající popis kategorie,
- výstup jsme exportovali do CSV souboru,
- pomocí pravidla Import datového souboru jsme CSV nahráli zpět do produktového feedu,
- popis kategorie jsme ke každému produktu přiřadili pomocí párovacího elementu s názvem kategorie.
Takto připravený obsah jsme ukládali do pomocného elementu. Ten se nemusel exportovat do finálního feedu, ale sloužil jako další zdroj kontextu, se kterým jsme pracovali přímo v promptu.
🛒 Obecné informace o e‑shopu
Dalším zdrojem kontextu byly obecné informace o e‑shopu. Nejde o data vztahující se ke konkrétnímu produktu, ale o rámec, ve kterém se celý sortiment pohybuje.
Tyto informace pomáhají jazykovému modelu lépe pochopit:
- co e‑shop prodává a na co se specializuje,
- kdo je cílová skupina a jaké jsou hlavní persony,
- jaké hodnoty, vize nebo směřování e‑shop má
- a případná specifika sortimentu (např. varianty produktů, specifické typy zboží).
Součástí tohoto kontextu mohou být i obecné informace o dopravě, vrácení zboží nebo dalších pravidlech, pokud jsou relevantní pro výslednou podobu popisků.
Jak jsme informace o e‑shopu připravili
Příprava těchto dat byla oproti jiným zdrojům relativně jednoduchá.
Postupovali jsme takto:
- pomocí jazykového modelu (např. ChatGPT) jsme si nechali připravit obecný popis e‑shopu,
- jako vstup jsme zadali název e‑shopu a jeho URL adresu,
- výsledný text jsme uložili do Markdown souboru,
- soubor jsme zpřístupnili přes Mergado Files.
Stejně jako u článků se tento obsah neukládal ke každému produktu zvlášť. Sloužil jako globální kontext, který jsme do promptu přidávali jen tam, kde to dávalo smysl.
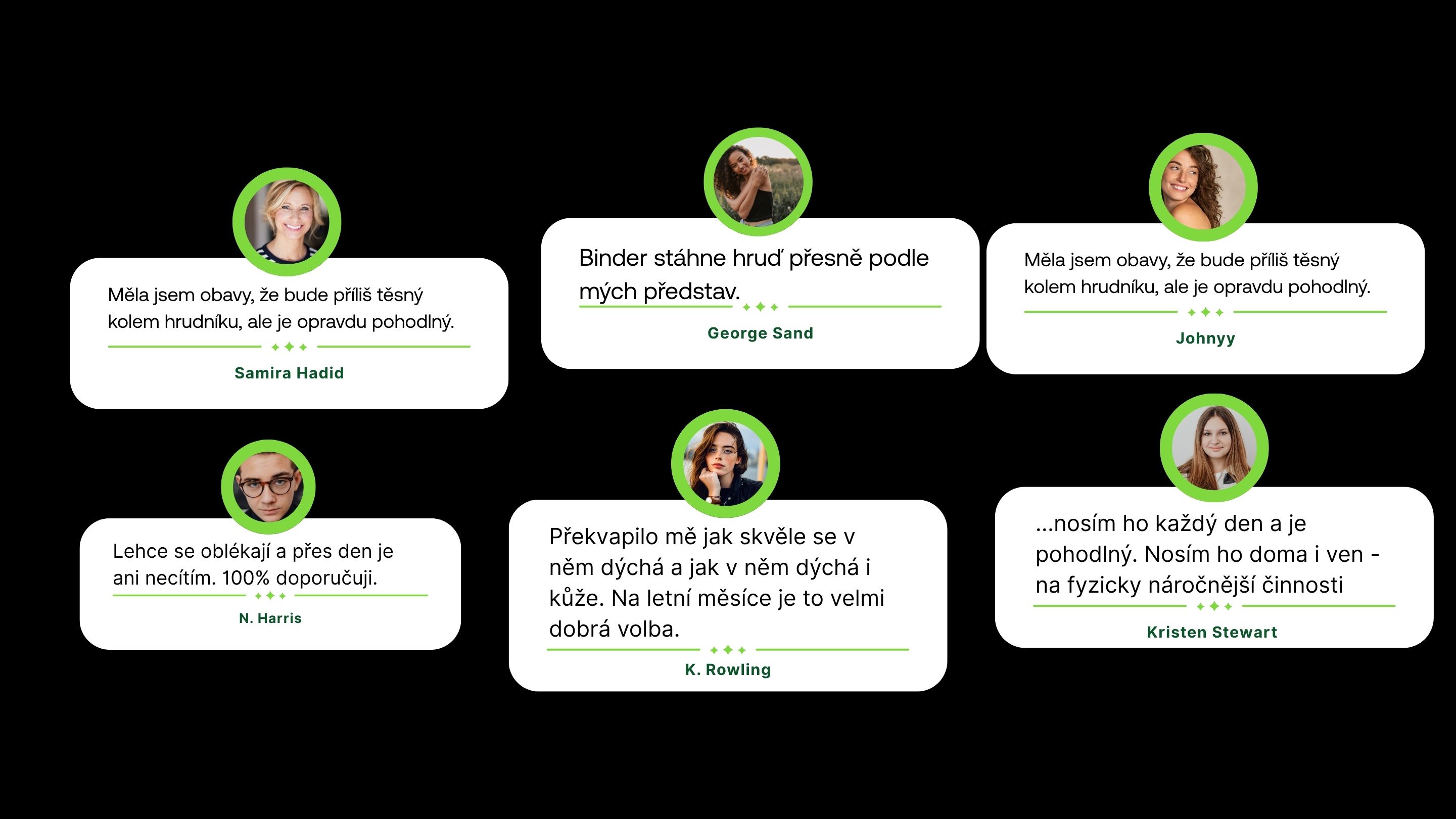
⭐ Recenze produktů
Recenze produktů patřily mezi nejcennější zdroje informací, ale zároveň představovaly největší výzvu z pohledu přípravy dat. Na rozdíl od článků nebo popisů kategorií totiž nejsou přirozeně strukturované pro práci na úrovni produktu.
Jejich hlavní přínos je ale jasný:
- obsahují reálné zkušenosti zákazníků,
- popisují praktické použití v běžném životě,
- upozorňují na detaily, na které si dát pozor,
- a často odpovídají na otázky, které se běžně objevují v Q&A.
Právě proto jsou recenze velmi silným zdrojem kontextu pro GPT Shopping.
Hlavní výzva: jedna recenze ≠ jeden produkt
Recenze jsou typicky vedené tak, že:
- každá recenze je samostatná položka,
- jeden produkt se v datech objevuje opakovaně,
- data nejsou připravená na úrovni produktu, ale jednotlivých hodnocení.
Pro naše potřeby jsme ale potřebovali dostat všechny recenze týkající se jednoho produktu k danému produktu ve feedu. To znamenalo recenze deduplikovat, sloučit a doplnit o souhrnné metriky.
Jak jsme recenze připravili
Zvolili jsme cestu úpravy dat mimo Mergado a jejich následný import.
Postup byl následující:
- recenze jsme stáhli z administrace Shoptetu do CSV souboru,
- data jsme otevřeli v Google Sheets,
- pomocí funkcí:
- UNIQUE jsme recenze deduplikovali,
- TEXTJOIN jsme sloučili texty recenzí ke konkrétnímu produktu,
- zároveň jsme zpracovali i číselné hodnoty:
- jednotlivá hodnocení,
- průměrné hodnocení,
- počet recenzí,
- výslednou tabulku jsme zveřejnili jako CSV,
- pomocí pravidla Import datového souboru jsme data nahráli zpět do produktového feedu,
- recenze a hodnocení jsme ukládali do pomocných elementů (např. product_reviews, product_rating).
Tyto elementy pak sloužily jako další vstup pro prompt při generování popisků.
Alternativní postup
Vyzkoušeli jsme i alternativní řešení založené na recenzních feedech z Google nebo Heureky.
Postup byl složitější:
- vytvořili jsme dva pomocné projekty v Mergadu,
- data jsme převedli do Shoptet dodavatelského XML formátu,
- využili jsme slučování variant, aby se produkt vyskytoval pouze jednou,
- recenze zůstaly zachované jako varianty,
- následně jsme data převedli do CSV a importovali do produktového feedu.
Tento postup je funkční, ale náročnější na nastavení a údržbu.
🏷️ Popisy značek
Popisy značek jsme využili jako doplňkový zdroj kontextu, který pomáhá jazykovému modelu lépe pochopit, kdo za produktem stojí a v jakém rámci se pohybuje.
Jejich přínos je především v tom, že:
- doplňují informace o výrobci,
- naznačují specializaci nebo zaměření značky,
- mohou přidat kontext k hodnotám nebo kvalitě produktů.
Nejde o klíčový zdroj pro každý produkt, ale v kombinaci s dalšími daty pomáhá dotvořit celkový obrázek.
Jak jsme popisy značek připravili
Využili jsme toho, že Shoptet umožňuje export značek do CSV.
Postup byl následující:
- export značek jsme nahráli do jednoduchého projektu v Mergadu,
- v projektu jsme upravili strukturu dat tak, abychom získali:
- název značky jako párovací prvek,
- popis značky jako hodnotu,
- výsledné CSV jsme pomocí pravidla Import datového souboru nahráli do produktového feedu,
- popisy značek jsme k produktům přiřadili podle názvu značky.
Stejně jako u ostatních zdrojů jsme tento obsah ukládali do pomocných elementů. Ty sloužily jako další vstupní data pro prompt, nikoli jako obsah určený přímo do výstupního feedu.
🤖 Optimalizace produktových popisků pomocí GPT
Jakmile jsme měli všechny zdroje obsahu připravené – ať už uložené v Markdown souborech přes Mergado Files nebo importované do produktového feedu jako pomocné elementy – přišla na řadu samotná optimalizace produktových popisků pomocí jazykového modelu.
Cílem už nebylo data jen shromáždit, ale aktivně je využít při generování obsahu, který je:
- kontextově bohatší,
- relevantnější pro GPT Shopping
- a zároveň konzistentní napříč celým sortimentem.
Pro tuto část jsme využili rozšíření Mergado Sources, které umožňuje pracovat s GPT modely přímo nad daty v Mergadu.
Použitý nástroj a jeho role
Rozšíření Mergado Sources slouží jako propojení mezi daty v Mergadu a jazykovým modelem. Umožňuje:
- definovat, z jakých elementů a zdrojů má model čerpat,
- pracovat s výběry produktů,
- zapisovat výstupy přímo zpět do feedu.
Díky tomu je možné generování popisků automatizovat a řídit ho pomocí stejných principů, jaké se v Mergadu používají i pro jiné úpravy dat.
Postup krok za krokem
Samotný proces optimalizace jsme rozdělili do několika jasných kroků. Díky tomu šel celý postup dobře testovat, ladit a postupně škálovat.
Postupovali jsme takto:
-
Aktivovali jsme rozšíření Mergado Sources
Rozšíření jsme propojili s OpenAI pomocí API tokenu získaného z účtu na platform.openai.com.
-
Vytvořili jsme nový element
Na stránce Elementy jsme vytvořili nový element, do kterého se měl zapisovat výstup z jazykového modelu.
-
Zvolili jsme zdroj dat
Jako zdroj jsme vybrali OpenAI a přiřadili výběr produktů, nad kterými se měl obsah generovat.
- Zvolili jsme výběr produktů
- Nastavili jsme parametry modelu
- míru kreativity (temperature) jsme ponechali na hodnotě 0,5,
- testovali jsme různé modely (např. GPT‑5, GPT‑5 Mini, GPT‑5 Nano).
👉 Konkrétní model doporučujeme vždy otestovat – výsledky se mohou lišit podle typu sortimentu.
-
Zvolili jsme cílový element
Výstup jsme zapisovali buď:
- do nového elementu,
- nebo přímo do existujícího elementu (např. pole Description v GPT Shopping feedu).
-
Otestovali jsme ukázkový výstup
Rozšíření umožňuje vygenerovat náhled výstupu pro náhodný produkt, což je velmi užitečné při ladění promptu.
-
Aplikovali jsme pravidla
Je potřeba počítat s tím, že pravidla se aplikují dvakrát,
- poprvé se data odešlou do OpenAI API,
- podruhé se vrácený výstup zapíše do cílového elementu.
👉 Mezi oběma kroky je vhodné nechat časovou rezervu, protože zpracování může trvat i desítky minut v závislosti na množství dat.
Kontrola výsledků a další možnosti
Po vygenerování popisků jsme:
- kontrolovali výsledný obsah u produktů,
- dál ladili samotný prompt,
- ověřovali konzistenci napříč sortimentem.
Stejný přístup je možné použít i pro optimalizaci produktových názvů. Zdroje dat už jsou připravené, takže postup je velmi podobný jako u popisků.
🏁 Závěr
V této případové studii jsme ukázali, jak lze pomocí Mergada systematicky optimalizovat produktové popisky a další data pro GPT Shopping. Nešlo jen o samotné generování textů, ale především o práci s kontextem a relevancí. Tedy o to, jaká data jazykovému modelu předáme a v jaké podobě.
Popsaný postup je sice založený na konkrétním e‑shopu a konkrétním technickém řešení, ale je dostatečně univerzální, aby šel aplikovat i na jiné projekty. Klíčové je pochopit logiku:
- vybrat relevantní zdroje obsahu,
- připravit je do strukturované podoby,
- cíleně je využít při práci s jazykovým modelem.
Pokud se rozhodnete tento přístup vyzkoušet i u svého e‑shopu, doporučujeme začít postupně. Testovat na menším vzorku produktů, ladit prompt a až poté řešení škálovat na celý sortiment.
Budeme rádi, když se s námi podělíte o své zkušenosti – jak se vám postup osvědčil, zda přinesl očekávané výsledky a případně jaké další zjednodušení nebo vylepšení jste při práci objevili. Držíme palce. 💪