






Na úvod ještě trochu teorie, která se do minulých dílů nevešla. V regulárních výrazech je možné pracovat také s negací, a to pomocí stříšky na začátku množiny znaků. Například:
- [^\d] odpovídá jednomu znaku, který není číslice,
- [^\s] odpovídá jednomu znaku, který není mezera (nejde o bílý znak).
Regulární výraz [^\s]*$ tak bude hledat jakékoliv znaky od konce řetězce po první mezeru (bílý znak). Takto je možné najít např. poslední slovo nebo číslo v řetězci (viz příklad, ke kterému jsme využili tuto stránku). 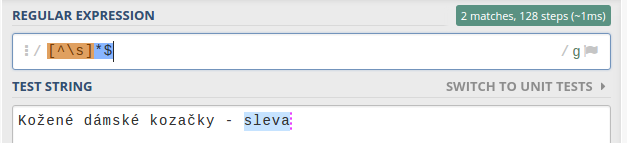
EAN
EAN může mnohdy způsobovat potíže při zobrazování produktů ve vašem feedu. Podíváme se tedy na dva časté problémy s jeho využitím.
1. Hromadné odstranění EAN kódů z popisku produktů
Pro odstranění EANu z DESCRIPTION nebo třeba CATEGORYTEXTU jednotlivých produktů potřebujeme využít pravidlo s regulárním výrazem, které vyhledá číselný řetězec o délce 8 – 13 znaků, včetně mezery za ním, a nahradí ho za “nic”. Využijeme tedy pravidlo typu najít a nahradit, přičemž v elementu CATEGORYTEXT budeme vyhledávat následující regulární výraz: \d{8,13}\s, a do pole pro nahrazení nezadáme nic. Toto pravidlo můžeme aplikovat na všechny produkty, není potřeba dělat speciální výběr - tam kde se EAN v popisku produktu nenajde, nic se nestane a pravidlo se neaplikuje. 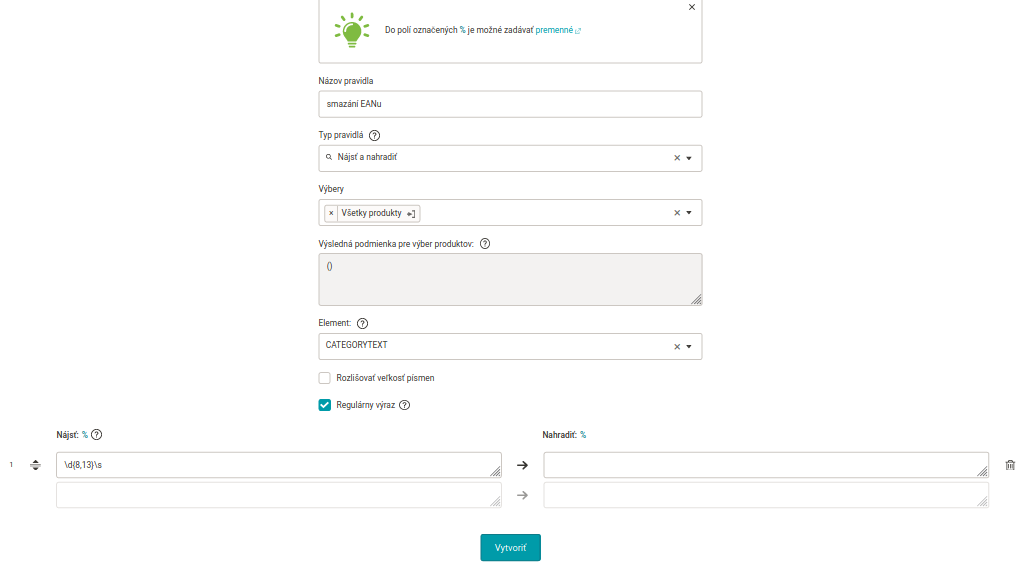
2. Kontrola EANu
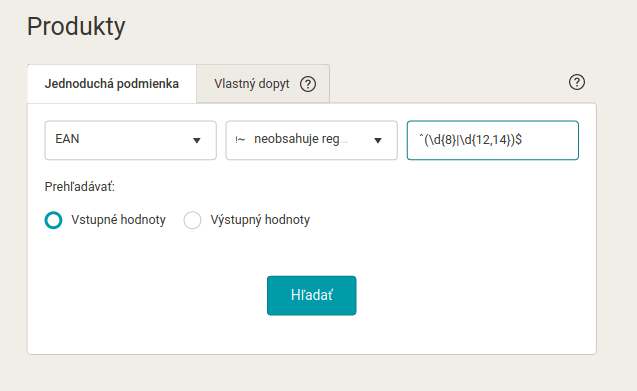
Chybná délka EANu může být také častým zdrojem potíží třeba při exportu dat na Google. Pomocí regulárních výrazů v Mergadu takovou chybu snadno odladíte. Řekněme, že chcete vyhledat všechny produkty, které mají EAN špatně – obsahuje jiný počet znaků než 8 nebo 12 – 14 (což jsou nejčastější délky EANu). Budeme tedy vyhledávat takové produkty, které v elementu EAN nemají právě 8 nebo právě 12 – 14 znaků. Tady využijeme stříšku z úvodu, případně v jednoduchém rozhraní Mergada příkaz „neobsahuje regulární výraz“: ^(\d{8}|\d{12,14})$
- Stříška a dolar označují začátek a konec řetězce, ve kterém vyhledáváme (oproti předchozímu příkladu tentokrát EAN neobklopuje další text).
- \d vyhledává číslice – buď přesně 8 libovolných číslic (osmička ve složené závorce) nebo (svislítko) přesně 12 – 14 libovolných číslic.
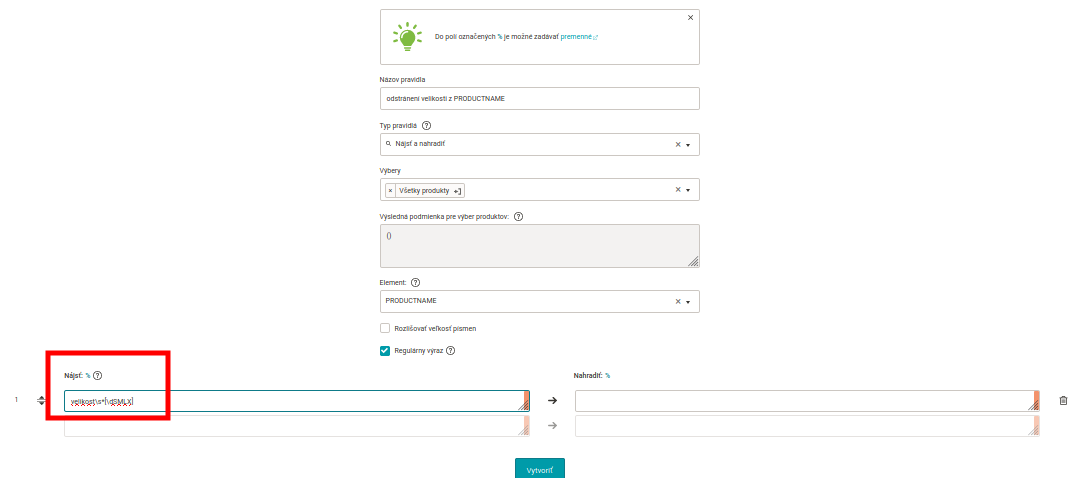
Odebrání velikosti z PRODUCTNAME
Některé srovnávače – například Glami – požadují, aby element PRODUCTNAME neobsahoval informaci o velikosti zboží, neboť pro ni má speciální element PARAM. V případě, že máte svoje produkty v e‑shopu takto pojmenované, potřebujete část názvu smazat u velkého množství položek. Jak na to? Pomocí pravidla najít a nahradit budeme hledat konkrétní regulární výraz: velikost\s*[\dSMLX]+ a nahrazovat za “nic”.Chceme totiž najít slovní spojení velikosti a písmena nebo čísla, které danou velikost označuje, přičemž mezi slovem „velikost“ a hodnotou může být libovolný počet mezer. Pojďme ale postupně a ukažme si, jak takový zápis vytvořit:
- velikost — hledáme řetězec, ve kterém je slovo „velikost“,
- hodnota velikosti – víme, že hodnoty označujeme písmenem (S, M, XL, …) a občas také kombinací písmena a čísla (např. 4XL). Proto použijeme zápis \d, který vyhledává všechna čísla od 0 do 9, a následně vyjmenujeme všechna písmena, z nichž alespoň jedno se ve výrazu nachází (proto hranaté závorky),
- toto označení může být kdekoli v řetězci, nepoužijeme tedy značky pro začátek nebo konec řetězce,
- mezi slovem “velikost” a samotnou hodnotou může být mezera (nebo více mezer) a nebo taky nemusí (např. velikostXL, velikost XL), proto použijeme vyhledávání mezer pomocí výrazu \s , hvězdička potom říká, že se tam má mezera vyskytovat 0 až nesčetněkrát,
- znaménko plus na konci řetězce určuje, že se celý hledaný výraz v hranatých závorkách vyskytuje v našem řetězci alespoň jednou.
Snad jste se v záplavě závorek a stříšek neztratili. Pokud ano, neváhejte se nám ozvat na fórum nebo zaslat e‑mail, rádi vám pomůžeme se najít!
Sledujte i další díl Jak na regulární výrazy v Mergadu nebo závěr seriálu o regulárních výrazech.


